HTTP-TCP
请求类型
- GET:发送请求来获取服务器上的某个资源
- POST:向URL指定的资源提交数据或附加新的数据
- PUT:向服务器提交数据,与POST方法类似。但是PUT指定了资源在服务器上的位置,而POST没有
- PATCH: 对已知资源进行局部更新
- HEAD:只请求页面首部
- DELETE:删除服务器上的资源
- OPTIONS:获取当前URL支持的请求方法
- TRACE:用于激活远程的、应用层的请求消息
- CONNECT:把请求连接转换到TCP/IP通道
GET和POST的区别
- GET在浏览器回退时是无害的, 而POST会再次提交请求(✔)
- GET产生的URL地址可以被保存, 而POST不可以
- GET请求会被浏览器主动cache, 而POST不会
- GET请求只能进行url编码, 而POST支持多种编码方式(✔)
- GET请求参数会被完整保留在浏览器历史记录中, 而POST中的参数不会被保留
- GET请求在URL中传输的参数是有长度限制的, 而POST没有(✔)
- 对参数的数据类型, GET只接受ASCLL字符, 而POST没有限制
- GET比POST更不安全, 因为参数直接暴露在URL上, 所以不能用来传递敏感信息(✔)
- GET参数通过URL传递, POST放在Request body中(✔)
- GET产生一个TCP包,POST产生两个TCP包。对于GET请求,浏览器会把
header和data一起发送数据,服务器响应200.对于POST请求,浏览器会先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200。(✔)
※ 我们可以给GET加上request body, 也可以在POST加上url参数. 这在技术上是行的通的.所以get和post实际上是一种约定的规则.
PUT和POST的区别
- PUT 方法是幂等的, 而 POST 的非幂等的
- PUT指定了资源在服务器上的位置,而POST没有
PUT和PATCH的区别
PUT是重新更新全部信息,PATCH是更新某部分的信息.
HTTP Keep-Alive
keep-alive的优点:
- 较少的 CPU 和内存的使用(由于同时打开的连接的减少了)
- 允许请求和应答的 HTTP 管线化
- 降低拥塞控制 (TCP 连接减少了)
- 减少了后续请求的延迟(无需再进行握手)
- 报告错误无需关闭 TCP
配置
Http1.1中默认开启Keep-Alive,也可以配置额外的参数:
1 | Connection: keep-alive |
TCP Keep Alive与HTTP Keep Alive的区别
HTTP Keep Alive主要是TCP连接的复用,避免建立过多的TCP连接;
TCP Keep Alive主要是保持TCP连接的存活,本质上是在发送心跳包;每隔一段时间给接受方发送一个探测包, 如果收到回应的ACK, 则认为连接还是存活的, 在超过一定重试次数之后, 还是没有收到对方的回应, 则丢弃该TCP连接.
管线化(为什么无需等待请求响应就能发送下一个请求)
本质上是将多个HTTP请求整批提交的技术, 而且在传输过程中不需要先等待服务端的回应. 管线化机制必须通过永久连接完成, 并且只有GET和HEAD请求可以进行管线化, 而POST则有所限制. 只能在HTTP1.1中启用.
关键在于把多个HTTP的请求消息同时塞入一个TCP分组中, 所以只要提交一个分组就能同时发出多个请求, 借此减少网络上多余的分组并降低线路负载.
HTTP请求报文
- 请求行:请求方法、URL字段、HTTP协议版本字段(使用空格分隔)
- 请求头:键值对的形式
1 | User-Agent:产生请求的浏览器类型 |
- 空行
- 请求体:携带的数据
HTTP响应报文
- 响应行:协议版本、状态码、状态码原因短语
- 响应头
- 空行
- 响应体
内容编码
内容编码能将数据容量变小。内容编码指明应用在实体内容上的编码格式, 并保持实体信息原样压缩. 内容编码后的实体由客户端接收并负责解码.
常用的内容编码有以下几种:
- gzip(GNU zip)
- compress(UNIX系统的标准压缩)
- deflate(zlib)
- identity(不进行编码)
分块传输编码
在Http通信过程中, 请求的编码实体资源尚未全部传输完成之前, 浏览器无法显示请求页面. 在传输大容量数据的时候, 通过把数据分割为多块, 能够让浏览器逐步显示页面。这种把实体主体分块的功能称为分块传输编码(Chunked Transfer Coding).分块传输编码会将实体分成多个部分(块), 每一块都会用16进制来标记块的大小, 而实体主体的最后一块会使用”0(CR+LF)”来标记.使用分块传输编码的实体主体会由接受的客户端负责解码, 恢复到编码前的实体主体.
HTTP响应状态码
2XX 成功:
- 200 OK, 表示从客户端发来的请求在服务器端被正确处理 ✨
- 201 Created, 请求已经被实现,而且有一个新的资源已经依据请求的需要而建立
- 202 Accepted, 请求已接受,但是还没执行,不保证完成请求
- 204 No content, 表示请求成功,但响应报文不含实体的主体部分
- 206 Partial Content, 进行范围请求 ✨
3XX 重定向:
- 301 moved permanently,永久性重定向,表示资源已被分配了新的 URL
- 302 found,临时性重定向,表示资源临时被分配了新的 URL ✨
- 304 not modified,表示服务器允许访问资源,但因发生请求未满足条件的情况
- 307 temporary redirect,临时重定向,和 302 含义相同, 但是不会改变请求方式
4XX 客户端错误:
- 400 bad request,请求报文存在语法错误 ✨
- 401 unauthorized,表示发送的请求需要有通过 HTTP 认证的认证信息 ✨
- 403 forbidden,表示对请求资源的访问被服务器拒绝 ✨
- 404 not found,表示在服务器上没有找到请求的资源 ✨
- 408 Request timeout, 客户端请求超时
- 409 Confict, 请求的资源可能引起冲突
5XX 服务器错误:
- 500 internal sever error,表示服务器端在执行请求时发生了错误 ✨
- 501 Not Implemented 请求超出服务器能力范围,例如服务器不支持当前请求所需要的某个功能,或者请求是服务器不支持的某个方法
- 503 service unavailable,表明服务器暂时处于超负载或正在停机维护,无法处理请求
- 505 http version not supported 服务器不支持http协议版本,或者拒绝支持在请求中使用的 HTTP 版本
302,303,307的区别
302 是 http1.0 的协议状态码,在 http1.1 版本的时候为了细化 302 状态码又出来了两个 303 和 307。
303 明确表示客户端应当采用 get 方法获取资源,他会把 POST 请求变为 GET 请求进行重定向。 307 会遵照浏览器标准,不会从 post 变为 get。
301与302对搜索引擎的影响
301 重定向是网页更改地址后对搜索引擎友好的最好方法,只要不是暂时搬移的情况,都建议使用 301 来做转址。 如果我们把一个地址采用 301 跳转方式跳转的话,搜索引擎会把老地址的PageRank等信息带到新地址,同时在搜索引擎索引库中彻底废弃掉原先的老地址。旧网址的排名等完全清零。
302容易被搜索引擎误判。
HTTP首部字段
分类
- 通用首部字段: 请求报文和响应报文都会使用的首部字段
- 请求首部字段: 客户端向服务器发送请求报文时使用的首部字段, 补充了请求的附加内容, 客户端信息, 响应内容相关优先级信息
- 响应首部字段: 从服务端向客户端返回响应报文时使用的首部, 补充了响应的附加内容, 也会要求客户端附加额外的内容信息
- 实体首部字段: 针对请求报文和响应报文的实体部分使用的首部, 补充了资源内容更新时间和实体有关的信息
通用首部字段(请求报文和响应报文都有的)
Cache-Control控制缓存 ✨Connection连接管理、逐跳首部 ✨Connetion: closeHTTP/1.1版本是默认持久连接的. 只要TCP连接不断开, 就可以一直发送HTTP请求, 持续不断, 没有上限.Upgrade可以用来检测HTTP协议以及其他协议是否可使用, 并用更高的版本进行通信.via代理服务器的相关信息, 可以用来追踪客户端与服务器之间的请求和响应报文的传输路径. 也可以用于避免请求回环的发生, 常常和trace请求一起使用.Warning告知用户一些与缓存相关的问题的警告, 格式如下:Warning: [警告码] [警告的主机:端口号] "[警告内容]" ([日期时间])Transfor-Encoding报文主体的传输编码格式 ✨Trailer会事先说明在报文主体后面记录了哪些首部字段, 可以应用在分块传输编码的时候.Pragma报文指令, 是历史遗留字段, 仅仅为了兼容而存在.Date创建报文的日期
请求头部字段
Accept客户端或者代理能够处理的媒体类型 ✨Accept-Encoding优先可处理的编码格式Accept-Language优先可处理的自然语言Accept-Charset优先可以处理的字符集Authorizationweb 的认证信息 ✨Host请求资源所在服务器, 是HTTP/1.1规范中唯一一个必须被包含在请求内的首部字段Expect期待服务器的特定行为If-Match比较实体标记Etag, 只有两个值匹配一致的时候, 服务器才会接受请求If-None-Match比较实体标记(ETage)与 If-Match 相反 ✨If-Modified-Since比较资源更新时间(Last-Modified)✨If-Unmodified-Since比较资源更新时间(Last-Modified),与 If-Modified-Since 相反 ✨If-Ranges告知服务器若指定的if-range字段值(ETag的值或者时间)与请求资源的ETag值或者时间相一致的时候, 作为范围请求处理. 反之, 返回全体资源Range实体的字节范围请求 ✨Proxy-Authorization代理服务器要求 web 认证信息From用户的邮箱地址User-Agent客户端程序信息 ✨Max-Forwrads最大的逐跳次数, 每经过一个代理服务器就减1, 可以用来检查请求路径的通信情况.TE传输编码的优先级Referer请求原始方的url, 可以知道URI是从哪个web页面发起的
响应首部字段
Accept-Ranges能接受的字节范围, 当不能处理范围请求时, 可以发送Accept-Ranges: noneAge告知客户端, 源服务器在多久之前创建了响应, 字段值单位为秒ETag能够表示资源唯一资源的字符串 ✨Location令客户端重定向的 URI, 基本用在配合30x的重定向请求时提供 ✨Proxy-Authenticate代理服务器要求客户端的验证信息Retry-After和状态码 503 一起使用的首部字段,表示下次请求服务器的时间Server服务器的信息 ✨Vary代理服务器的缓存信息控制, 比如Vary: Accept-Language表示只能对相同自然语言的请求返回缓存WWW-Authenticate服务器要求客户端的验证信息
HTTP1.1缺点
针对同一域名下的请求有一定数量限制,超过限制数目的请求会被阻塞。
HTTP2缺点
所有压力都集中在底层一个TCP连接上,TCP很可能是下一个性能瓶颈。多个请求是在同一个 TCP 管道中,这样当 HTTP 2.0 出现丢包时,整个 TCP 都要开始等待重传,那么就会阻塞该 TCP连接中的所有请求。
HTTP3
HTTP3是在保持QUIC稳定性的同时,使用UDP来实现高速度, 同时又不会牺牲TLS的安全性.
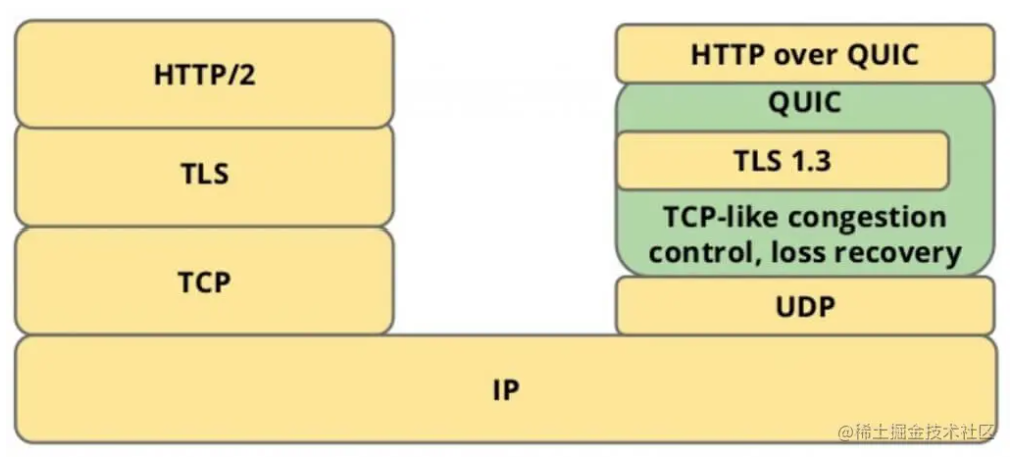
1. 安全性-TLS(与https中SSL/TLS建立连接的过程是一致的)
- 首次连接, 客户端发送
Inchoate Client Hello, 用于请求连接; - 服务端生成g, p, a, 根据g, p, a算出A, 然后将g, p, A放到Server Config中在发送
Rejection消息给客户端. - 客户端接收到g,p,A后, 自己再生成b, 根据g,p,a算出B, 根据A,p,b算出初始密钥K, B和K算好后, 客户端会用K加密HTTP数据, 连同B一起发送给服务端.
- 服务端接收到B后, 根据a,p,B生成与客户端同样的密钥, 再用这密钥解密收到的HTTP数据. 为了进一步的安全(前向安全性), 服务端会更新自己的随机数a和公钥, 在生成新的密钥S, 然后把公钥通过
Server Hello发送给客户端. 连同Server Hello消息, 还有HTTP返回数据.
2. 连接迁移
TCP连接基于四元组(源IP, 源端口, 目的IP, 目的端口), 切换网络时至少会有一个因素发生变化, 导致连接发送变化. 当连接发生变化时, 如果还是用原来的TCP连接, 则会导致连接失败, 就得等到原来的连接超时后重新建立连接, 所以我们有时候发现切换到一个新的网络时, 即使网络状况良好, 但是内容还是需要加载很久. 如果实现的好, 当检测到网络变化时, 立即建立新的TCP连接, 即使这样, 建立新的连接还是需要几百毫秒时间.
QUIC不受四元组的影响, 当这四个元素发生变化时, 原连接依然维持. 原理如下:QUIC不以四元素作为表示, 而是使用一个64位的随机数, 这个随机数被称为Connection ID, 即使IP或者端口发生变化, 只要Connection ID没有变化, 那么连接依然可以维持.
3. 队头阻塞/多路复用
TCP是个面向连接的协议, 即发送请求后需要收到ACK消息, 以确认对象已接受数据. 如果每次请求都要在收到上次请求的ACK消息后再请求, 那么效率无疑很低. HTTP1.1中的解决办法:提出了Pipeline技术, 允许一个TCP连接同时发送多个请求.
问题:在这样的背景下, 队头阻塞发生了. 比如, 一个TCP连接同时传输10个请求, 其中1,2,3个请求给客户端接收, 但是第四个请求丢失, 那么后面第5-10个请求都被阻塞. 需要等第四个请求处理完毕后才能被处理. 这样就浪费了带宽资源.
HTTP2使用多路复用解决了上述问题。在HTTP2中,每个请求都被拆分为多个帧,通过一个TCP连接同时被传输,这样即使一个请求被阻塞,也不会影响其他请求。虽然HTTP2可以解决请求粒度下的阻塞,但是没能从根本解决问题。因为HTTP2中,每个请求会被拆分成多个帧(frame),不同请求的帧组合成一个流(stream),流是TCP上的逻辑传输单元。
如下所示,stream1已正确送达,stream2中的frame丢失了一个,TCP处理数据是有严格的先后顺序,先发送的frame要先被处理,这样就会要求发送方发送第三个frame,stream3和stream4虽然已经到达但却不能被处理,那么这条链路就会被阻塞。
QUIC是如何解决队头阻塞的问题的? 主要有两点:
- QUIC的传输单位是Packet, 加密单元也是Packet, 整个加密, 传输, 解密都基于Packet, 这就能避免TLS的阻塞问题.
- QUIC基于UDP, UDP的数据包在接收端没有处理顺序, 即使中间丢失一个包, 也不会阻塞整条连接. 其他的资源会被正常处理.
UDP 本身没有建立连接这个概念,并且 QUIC 使用的 stream 之间是相互隔离的,不会阻塞其他 stream 数据的处理,所以使用 UDP 并不会造成队头阻塞。
4. 拥塞控制
拥塞控制的目的是避免过多的数据一下子涌入网络, 导致网络超出最大负荷.
QUIC重新实现了TCP协议中的Cubic算法进行拥塞控制, 下面是QUIC改进的拥塞控制的特性:
1) 热插拔
TCP中如果要修改拥塞控制策略, 需要在系统层面操作, QUIC修改拥塞控制策略只需要在应用层操作, 并且QUIC会根据不同的网络环境,、用户来动态选择拥塞控制算法.
2)前向纠错
QUIC使用前向纠错(FEC, Forword Error Correction)技术增加协议的容错性. 一段数据被切分为10个包后, 一次对每个包进行异或运算, 运算结果会作为FEC包与数据包一起被传输, 如果传输过程中有一个数据包丢失, 那么就可以根据剩余9个包以及FEC包推算出丢失的那个包的数据, 这样就大大增加了协议的容错性.
这是符合现阶段网络传输技术的一种方案, 现阶段带宽已经不是网络传输的瓶颈, 往返时间才是, 所以新的网络传输协议可以适当增加数据冗余, 减少重传操作.
3)单调递增的Packet Number
TCP为了保证可靠性, 使用Sequence Number和ACK来确认消息是否有序到达, 但这样的设计存在缺陷.超时发生后客户端发起重传, 后来接受到了ACK确认消息, 但因为原始请求和重传请求接受到的ACK消息一样, 所以客户端就不知道这个ACK对应的是原始请求还是重传请求,这就会造成歧义,从而导致计算得到的RTT可能会出现偏大(认为是原始的ACK)或偏小(认为是重传的ACK)的情况。
QUCI解决了上面的的歧义问题, 与Sequence Number不同, Packet Number严格单调递增, 如果Packet N丢失了, 那么重传时Packet的标识就不会是N, 而是比N大的数字, 比如N+M, 这样发送方接收到确认消息时, 就能方便的知道ACK对应的原始请求还是重传请求.
4)流量控制
TCP 会对每个TCP连接进行流量控制, 流量控制的意思是让发送方不要发送太快, 要让接收方来得及接受, 不然会导致数据溢出而丢失, TCP的流量控制主要通过滑动窗口来实现的. 可以看到, 拥塞控制主要是控制发送方的发送策略, 但没有考虑接收方的接收能力.
QUIC只需要建立一条连接, 在这条连接上同时传输多条Stream, 好比有一条道路, 量都分别有一个仓库, 道路中有很多车辆运送物资. QUIC的流量控制有两个级别: 连接级别(Connection Level)和Stream 级别(Stream Level).
对于单条的Stream的流量控制: Stream还没传输数据时, 接收窗口(flow control recevice window)就是最大接收窗口, 随着接收方接收到数据后, 接收窗口不断缩小. 随着数据不断被处理, 接收方就有能力处理更多数据. 当满足(flow control receivce offset - consumed bytes) < (max receive window/2)时, 接收方会发送WINDOW_UPDATE frame告诉发送方你可以再多发送数据, 这时候flow control receive offset就会偏移, 接收窗口增大, 发送方可以发送更多数据到接收方.
Stream级别对防止接收端接收过多数据作用有限, 更需要借助Connection级别的流量控制. 理解了Stream流量那么也很好理解Connection的流控. Stream中:
1 | 复制代码接收窗口=最大接受窗口 - 已接收数据 |
而对于Connection来说:
1 | 复制代码接收窗口 = Stream1 接收窗口 + Stream2 接收窗口 + ... + StreamN 接收窗口 |
QUIC到底快在哪里呢?(连接建立快)
HTTP 协议在传输层是使用了 TCP 进行报文传输,而且 HTTPS 、HTTP/2.0 还采用了 TLS 协议进行加密,这样就会导致三次握手的连接延迟:即 TCP 三次握手(一次)和 TLS 握手(两次),如下图所示。
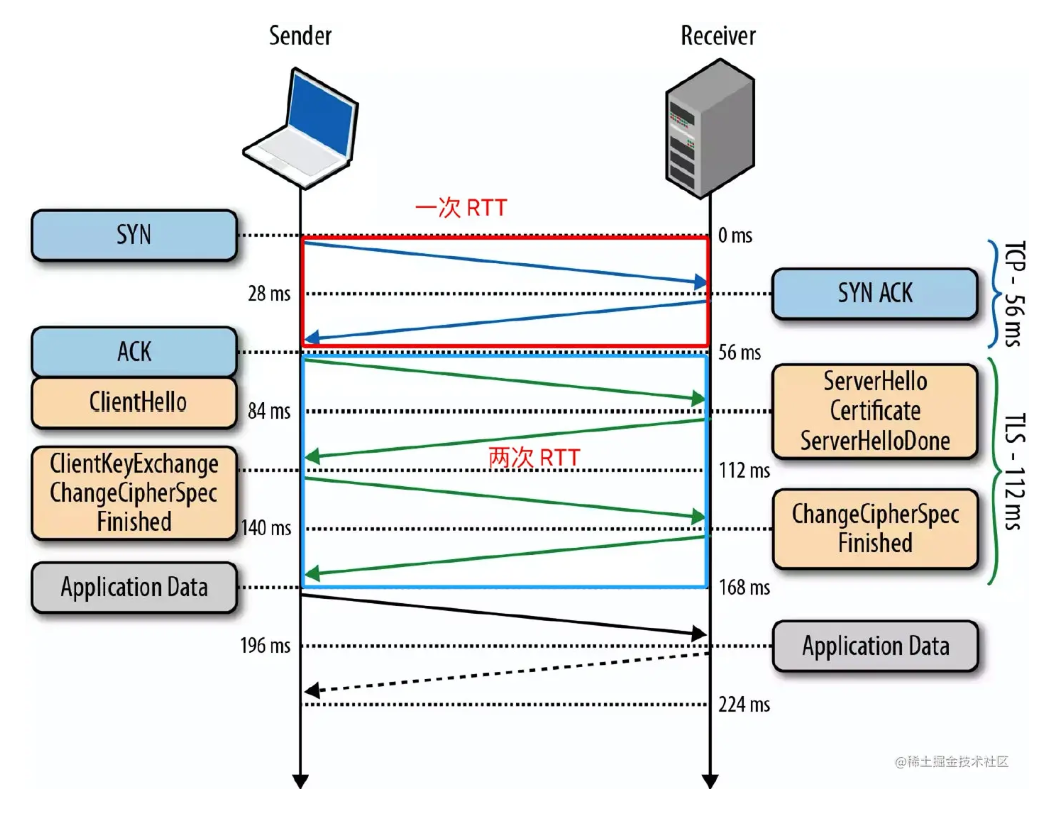
相比之下,QUIC 的握手连接更快,因为它使用了 UDP 作为传输层协议,这样能够减少三次握手的时间延迟。而且 QUIC 的加密协议采用了 TLS 协议的最新版本 TLS 1.3,相对之前的 TLS 1.1-1.2,TLS1.3 允许客户端无需等待 TLS 握手完成就开始发送应用程序数据的操作,可以支持1 RTT 和 0 RTT,从而达到快速建立连接的效果。
QUIC数据重传
QUIC将上层数据包,比如HTTP3数据包,分成多个帧,然后组装成一个Packet 发送。每个帧都会有一个定时器,如果在规定时间内收不到对应的ack,就重传对应的帧,还是通过packet,如果有其他帧一块,就凑成一个packet,如果没有,就自己用一个packet。
QUIC场景的应用场景
主要用于低延迟和可靠的场景
- 实时web和移动应用
- 车联网和网联汽车
- 云计算
- 支付和电商应用




